
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- WSL
- 데이터분석취업
- 내일배움카드
- 프로그래머스
- 데이터분석
- 코딩연습
- Python
- SQL
- 학습일지
- 데이터분석부트캠프
- qgis
- 코딩테스트
- 패스트캠퍼스부트캠프
- 데이터분석가
- 국비지원취업
- 패스트캠퍼스데이터분석부트캠프
- 코테문제풀이
- mysql
- 국비지원교육
- 아나콘다
- 패스트캠퍼스
- K디지털기초역량훈련
- 부트캠프
- bigquery
- 패스트캠퍼스기자단
- Programmers
- shp
- 코딩테스트문제풀이
- sql강의
- 국비지원
- Today
- Total
데이터 리터러시를 위한 발자취
[패스트캠퍼스] SQL 강의 학습후기 2주차 본문
국비지원교육으로 수강 중인 SQL 강의 1주차 학습후기에 이어 2주차 학습후기를 시작해보겠습니다.
이번 2주차부터는 조금씩 SQL 쿼리 로직에 대해서도 이해해야 실습 때 에러없이 넘어갈 수 있었습니다.
어쩌면 python의 문법과는 약간 다르지만 유사한 구성들이 있어서 조금 더 이해하기 수월했던 느낌이지만..
책으로만 배우는 것보단 확실히 영상으로 익히는 게 더 도움되는 것 같습니다.
특히 JOIN절은 다수의 테이블을 전처리 할 때 종종 쓰이는 부분이기에.. 정리해두었지만 복습은 필수일 것 같네요.
다른 분야도 마찬가지지만 역시 공부의 끝은 없다는게 느껴지는 2주차입니다.
6. 데이터 그룹화하기
1) 데이터 그룹화하기 (GROUP BY)
2) 그룹에 조건 주기(HAVING)
3) 다양한 그룹함수 알아보기(COUNT, SUM, AVG, MINMAX)
4) [TIP] 쿼리 실행순서 알아보기
1) 데이터 그룹화하기
- GROUP BY : 컬럼에서 동일한 값을 가지는 로우를 그룹화하는 키워드
> GROUP BY 컬럼이름 *엑셀 피벗기능과 유사
* 여러 컬럼으로도 그룹화 가능, 키워드 뒤에 컬럼이름 복수개 입력
SELECT GROUP BY 컬럼이름, ..., 그룹함수
FROM 테이블이름
WHERE 조건식
GROUP BY 컬럼이름;2) 그룹에 조건 주기(HAVING)
가져올 데이터 그룹에 조건을 지정해주는 키워드
* 조건식이 참인 그룹만 선택함
SELECT 컬럼이름, ..., 그룹함수
FROM 테이블이름
WHERE 조건식
GROUP BY 컬럼이름
HAVING 조건식;3) 다양한 그룹함수 알아보기(COUNT, SUM, AVG, MINMAX)
- COUNT : 그룹의 값의 수를 세는 함수
> SELECT, HAVING 절에서 사용, GROUP BY가 없는 쿼리에서도 사용가능
> COUNT(1)은 하나의 값을 1로 세어주는 표현
SELECT 컬럼이름, ..., COUNT(컬럼이름)
FROM 테이블이름
GROUP BY 컬럼이름
HAVING 조건문;- SUM : 그룹의 합을 계산하는 함수
> SELECT, HAVING 절에서 사용, GROUP BY가 없는 쿼리에서도 사용가능
SELECT 컬럼이름, ..., SUM(컬럼이름)
FROM 테이블이름
GROUP BY 컬럼이름
HAVING 조건문;- AVG : 그룹의 평균을 계산하는 함수
SELECT 컬럼이름, ..., AVG(컬럼이름)
FROM 테이블이름
GROUP BY 컬럼이름
HAVING 조건문;- MIN : 그룹의 최소값을 반환하는 함수
- MAX : 그룹의 최대값을 반환하는 함수
* 상기 그룹함수와 동일함
4) [TIP] 쿼리 실행순서 알아보기
| 키워드 | 문법 | 작성순서 | 실행순서 |
| SELECT | SELECT 컬럼이름 | 1 | 5 |
| FROM | FROM 테이블이름 | 2 | 1 |
| WHERE | WHERE 조건식 | 3 | 2 |
| GROUP BY | GROUP BY 컬럼이름 | 4 | 3 |
| HAVING | HAVING 조건식 | 5 | 4 |
| ORDER BY | ORDER BY 컬럼이름 | 6 | 6 |
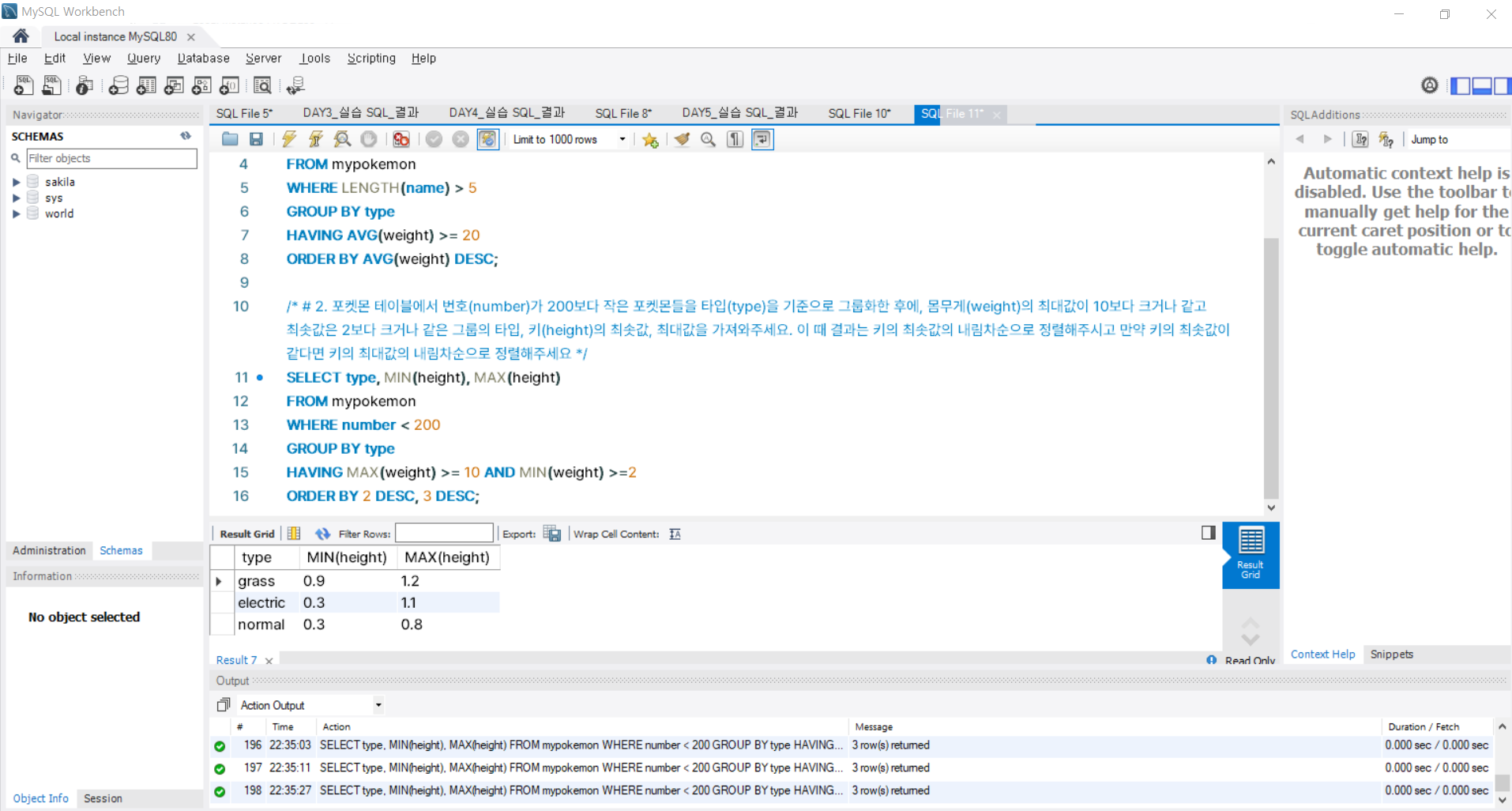
5. [실습]데이터를 그룹화해서 통계를 내보자
7. 규칙만들기
1) 조건만들기(IF, IFNULL)
2) 여러조건 한번에 만들기(CASE)
3) 함수만들기(CREATE, FUNCTION)
1) 조건만들기(IF, IFNULL)
- IF : SELECT절에서 사용하며, 결과 값을 새로운 컬럼으로 반환함
IF(조건식, 참일 때 값, 거짓일 때 값) -- SELECT 절에서 사용- IFNULL : 데이터의 NULL여부를 확인해 NULL이라면 새로운 값을 반환하는 함수(결과값 새로운 컬럼으로 반환)
IFNULL(컬럼이름, NULL일때 값) -- SELECT 절에서 사용
2) 여러조건 한번에 만들기(CASE)
- ELSE 문장 생략 시 NULL값 반환함
- 조건을 여러개 사용할 때 이용되며, END 문장은 필수 입력되어야함
- 사용방법에 따라 크게 2가지로 문장 구성할 수 있음
# CASE_1
CASE
WHEN '조건식1' THEN '결과값1'
WHEN '조건식2' THEN '결과값2' -- 조건식1에 해당되지 않을 때 조건식2로 넘어옴
ELSE '결과값3' -- 조건식 1,2 모두 F일 때 결과값3을 출력함
END
# CASE_2
CASE 컬럼이름
WHEN '조건값1' THEN '결과값1'
WHEN '조건값2' THEN '결과값2' -- 조건값1에 해당되지 않을 때 조건식2로 넘어옴
ELSE '결과값3' -- 조건값 1,2 모두 F일 때 결과값3을 출력함
END
/* 만약 ELSE 문장 없이 CASE~END를 사용하면 조건식 1,2에 해당되지 않는 값은 null 처리됨 */
3) 함수만들기(CREATE, FUNCTION)
- MySQL Workbench 기준 함수 생성 시 기본 쿼리문 외 추가 작성 필요한 부분 있음
- CREATE~BEGIN~END 문장 구조 암기 필요
# MySQL Workbench에서 함수 생성 시 주의할 점
SET GLOBAL log_bin_trust_function_creators=1; --사용자 계정에 function create 권한 생성
DELIMITER // -- 함수의 시작 지정
# 기본 쿼리문 형식
CREATE FUNCTION [함수이름] ([입력값이름1] [데이터타입1], [입력값이름2][데이터타입2],...)
RETURNS [결과값 데이터타입]
BEGIN
DECLARE [임시값이름1][데이터타입1];
DECLARE [임시값이름2][데이터타입2];
SET [임시값이름1] = [입력값이름1];
SET [임시값이름2] = [입력값이름2];
쿼리;
RETURN 결과값;
END
//
DELIMITER ; -- 함수의 끝 지정(※세미클론 앞에 한칸 띄우기 필수, 이어붙이면 에러 뜸)# 함수 활용 예시
# 형식으로만 남겨두면 다시 봤을 때 헷갈릴 것 같아 예시 내 문장별 해석 추가하여 작성
CREATE FUNCTION getability(attack INT, defense INT) -- getability 함수에 attack(INT),defense(INT)값 생성
RETURNS INT -- 최종결과값 데이터 타입 설정(INT)
BEGIN
DECLARE a INT; -- 임시값 a(INT) 설정
DECLARE b INT; -- 임시값 b(INT)) 설정
DECLARE ability INT; -- 임시값 ability(INT) 설정
SET a = attack; -- 임시값 a에 attack 값 치환
SET b = defense; -- 임시값 b에 defense 값 치환
SELECT a+b INTO ability; -- a(attack)+b(defense) 값을 ability에 치환
RETURN ability; -- 결과값은 ability로 설정함으로써, getability를 구하는 함수 생성 완료
END- 함수 삭제하기
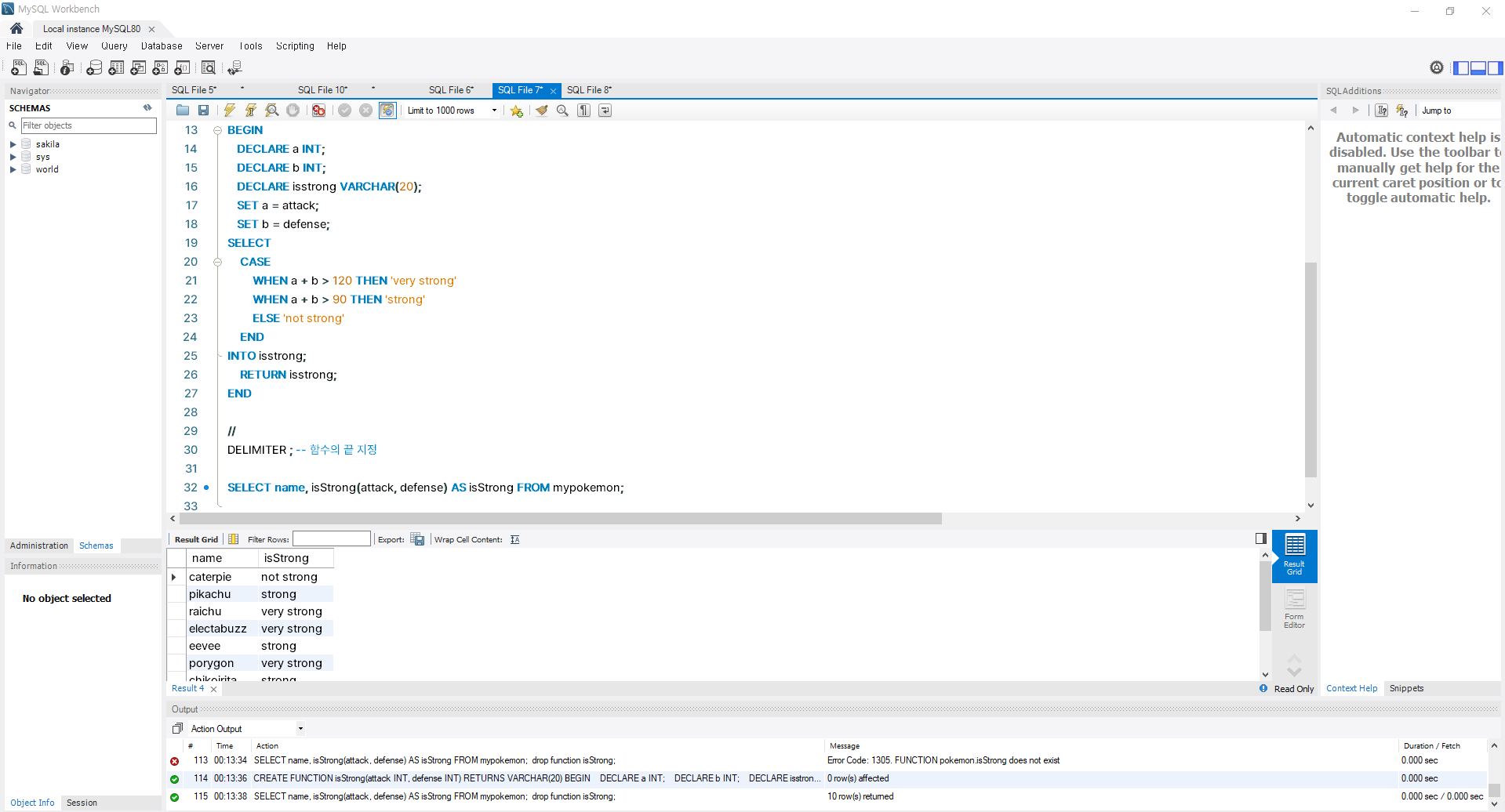
DROP FUNCTION [함수이름];4) [실습] 함수를 만들고 사용해보자
- 실습 당시, [ DELIMITER ; ] 함수의 끝을 지정해주는 끝문장 중간에 세미클론을 붙이지 않아 에러 뜸
8. 테이블 합치기
1) 테이블 합치기(JOIN)
2) 기준으로 테이블 합치기(INNER JOIN)
3) 한쪽을 기준으로 테이블 합치기(LEFT, RIGHT JOIN)
4) 다양한 방식으로 테이블 합치기(OUTER, CROSS, SELF JOIN)
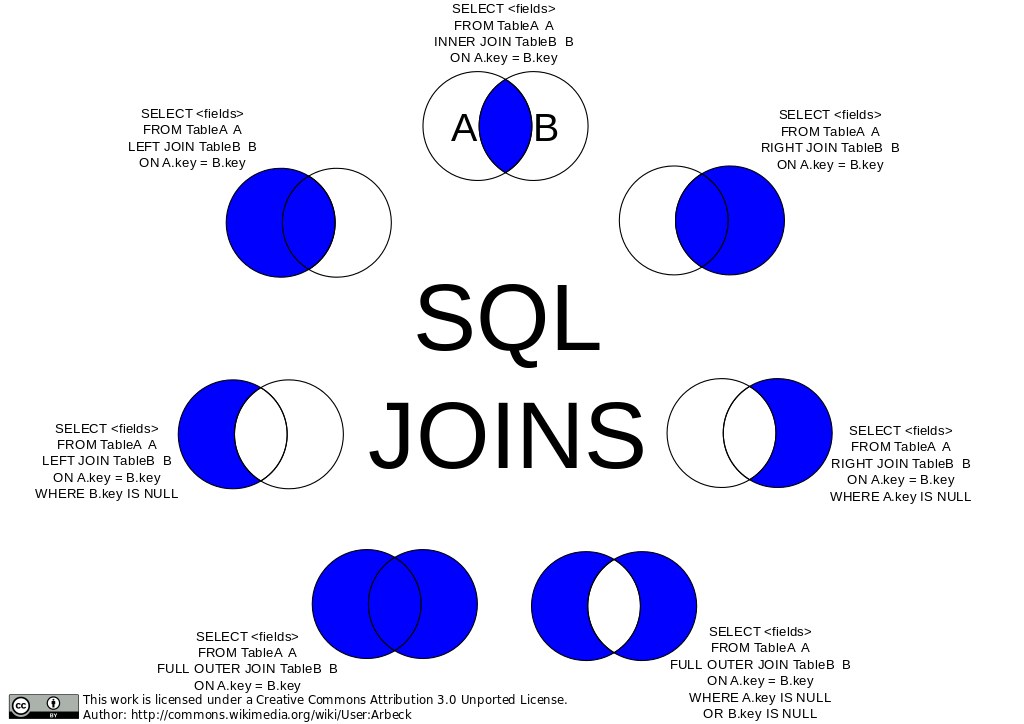
1) 테이블 합치기(JOIN)
- 같은 의미를 가지는 컬럼의 값을 기준으로 테이블을 합칠 때 사용함
> 예로, 테이블 A와 B를 JOIN할때 테이블 A와 B에 공통으로 존재하는 컬럼 기준 JOIN 수행함
- JOIN의 종류에 따라 크게 6가지로 구성됨
> INNER JOIN, LEFT JOIN, RIGHT JOIN, OUTER JOIN, CROSS JOIN, SELF JOIN
2) 기준으로 테이블 합치기(INNER JOIN)
- 'INNER' 없이 JOIN으로만 작성 시, 자동으로 INNER JOIN으로 인식됨
- 두 테이블 모두에 있는 값만 합치기(=교집합)
# 기본 쿼리문
SELECT [컬럼이름]
FROM [테이블 A 이름]
INNER JOIN [테이블 B 이름]
ON [테이블 A 이름].[컬럼 A 이름] = [테이블 B 이름].[컬럼 B 이름]
WHERE 조건식;3) 한쪽을 기준으로 테이블 합치기(LEFT, RIGHT JOIN)
- LEFT JOIN : 왼쪽 테이블에 있는 값만 합치기
- RIGHT JOIN : 오른쪽 테이블에 있는 값만 합치기
> JOIN 시, 알 수 없는 값에 대해 NULL값으로 출력됨(LEFT, RIGHT JOIN 모두 공통됨)
# 기본 쿼리문 (LEFT JOIN, RIGHT JOIN)
SELECT [컬럼이름]
FROM [테이블 A 이름]
LEFT JOIN [테이블 B 이름] -- RIGHT JOIN 위치함
ON [테이블 A 이름].[컬럼 A 이름] = [테이블 B 이름].[컬럼 B 이름]
WHERE 조건식;4) 다양한 방식으로 테이블 합치기(OUTER, CROSS, SELF JOIN)
- OUTER JOIN : 두 테이블에 있는 모든 값을 합쳐야 사용함 (=합집합)
* MySQL에는 존재하지 않는 키워드이기에 LEFT JOIN + RIGHT JOIN을 함께 사용하여야 함
** (참고)상기 이미지의 경우, FULL OUTER JOIN에 대한 설명이 있지만, MySQL Workbench에서는 동작안함
지원되지 않는 이유를 찾아보니, FULL OUTER JOIN은 ANSI SQL 구문으로 RDBMS에서 지원되나,
MySQL, MariaDB에서는 지원되지 않는다고 함
# 기본쿼리문
SELECT [컬럼이름]
FROM [테이블 A 이름]
LEFT JOIN [테이블 B 이름]
ON [테이블 A 이름].[컬럼 A 이름] = [테이블 B 이름].[컬럼 B 이름]
UNION -- ※ 두 쿼리의 결과 중복을 제외하고 병합하는 집합 연산자
SELECT [컬럼이름]
FROM [테이블 A 이름]
RIGHT JOIN [테이블 B 이름]
ON [테이블 A 이름].[컬럼 A 이름] = [테이블 B 이름].[컬럼 B 이름];- CROSS JOIN : 두 테이블에 있는 모든 값을 각각 합치기
# 기본쿼리문
SELECT [컬럼이름]
FROM [테이블 A 이름]
CROSS JOIN [테이블 B 이름] -- ON 키워드 제외되어도 무방함
WHERE 조건식;- SELF JOIN : 같은 테이블에 있는 값 합치기
> 같은 테이블의 값을 병합하는 방식이기에, JOIN할 테이블마다 별명(ALIAS)를 설정해줘야 함
# 기본쿼리문
SELECT [컬럼이름]
FROM [테이블 A 이름] AS t1
INNER JOIN [테이블 A 이름] AS t2
ON t1.[컬럼 A 이름] = t2.[컬럼 B 이름]
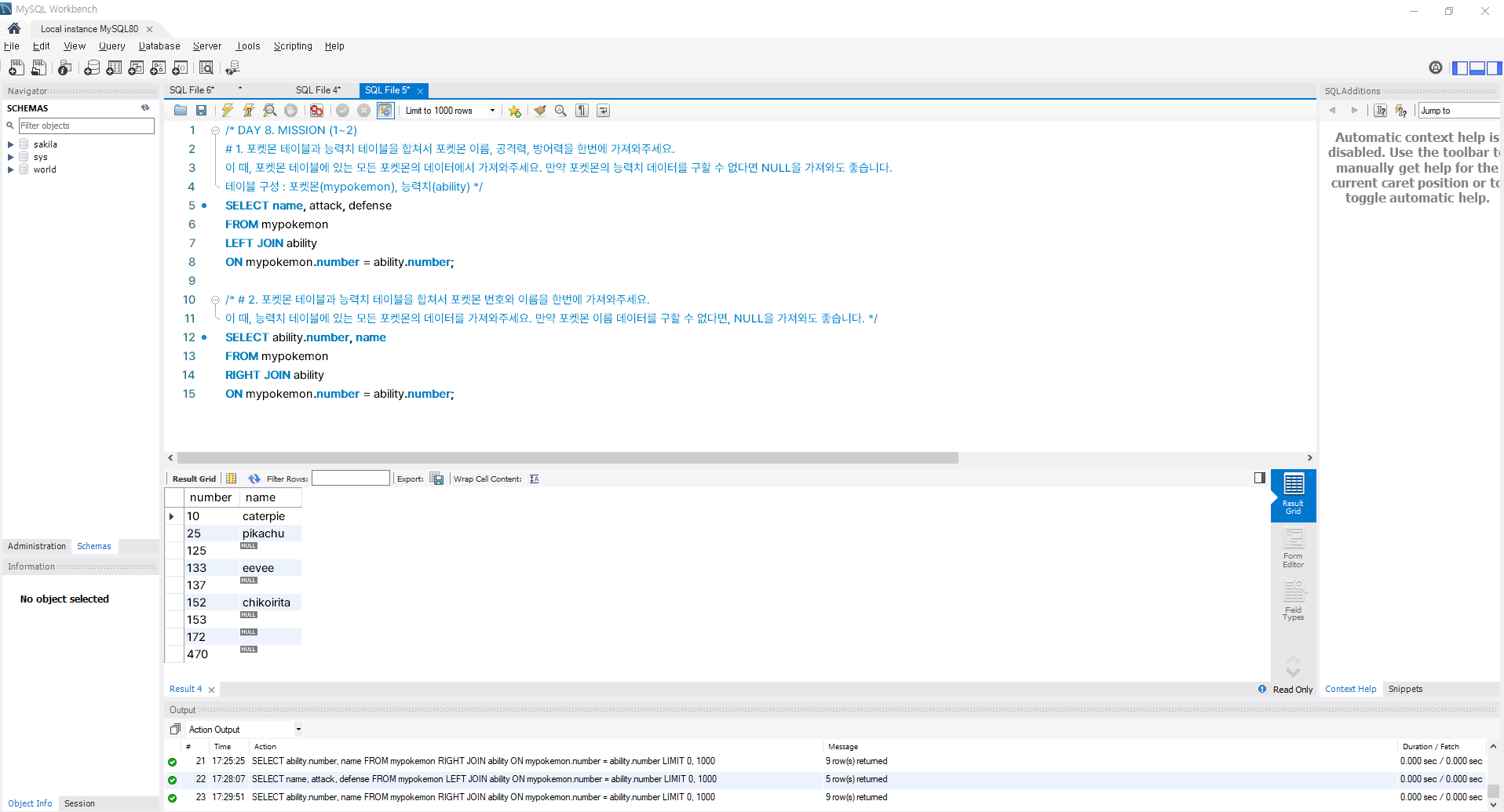
WHERE 조건식;5) [실습] 다양한 방식으로 테이블을 합쳐보자
- Mission 2 진행 시, "Error Code: 1052. Column 'number' in field list is ambiguous" 란 에러 발생
> 'number'란 컬럼이 두 테이블 모두 존재하기에 발생한 에러로, 어떤 테이블의 'number'을 사용할 것인지 SELECT절에서 명시하면 에러 해결됨
9. 여러 테이블 한번에 다루기
1) 데이터에 데이터 더하기 (UNION, UNION ALL)
2) 데이터에서 데이터 빼기(교집합, 차집합)
1) 데이터에 데이터 더하기 (UNION, UNION ALL) | = 합집합
※ 쿼리 A와 B의 결과 값의 개수는 같아야 함(=동일한 컬럼의 수)
> ODDER BY는 쿼리 가장 마지막에 작성 가능하며, 쿼리 A에서만 가져온 컬럼으로만 가능
- UNION : 동일한 값은 제외하고 결과값 출력함
# 기본 쿼리문
SELECT [컬럼이름]
FROM [테이블 A 이름]
UNION
SELECT [컬럼이름]
FROM [테이블 B 이름];
-- 테이블 간 병합하려는 조건에 따라 WHERE절, ORDER BY절 등 사용 가능함- UNION ALL : 동일한 값도 포함하여 결과값 출력함
# 기본 쿼리문
SELECT [컬럼이름]
FROM [테이블 A 이름]
UNION ALL
SELECT [컬럼이름]
FROM [테이블 B 이름];
-- 테이블 간 병합하려는 조건에 따라 WHERE절, ORDER BY절 등 사용 가능함2) 데이터에서 데이터 빼기(교집합, 차집합)
- 교집합 (INTERSECT) : 두 개의 테이블에 대해 겹치는 부분을 추출하는 연산자
> 추출 후 중복된 결과 제거하여 출력됨
# 기본 쿼리문
SELECT [컬럼이름]
FROM [테이블 A 이름] AS A
INNER JOIN [테이블 B 이름] AS B
ON A.[컬럼 1 이름] = B.[컬럼 2 이름] AND ... AND A.[컬럼 n 이름] = B.[컬럼 n 이름]- 차집합 (EXCEPT) : 두 개의 테이블에 대해 겹치는 부분을 테이블 A에서 제외하여 추출하는 연산자
# 기본 쿼리문
-- 차집합 확인하고 싶은 컬럼은 모두 기준으로 두어야 함(ON절)
SELECT [컬럼이름]
FROM [테이블 A 이름] AS A
LEFT JOIN [테이블 B 이름] AS B
ON A.[컬럼 1 이름] = B.[컬럼 2 이름] AND ... AND A.[컬럼 n 이름] = B.[컬럼 n 이름]
WHERE B.[컬럼이름] IS NULL;3) [실습] 여러 테이블의 데이터를 한번에 조회해보자(UNION)
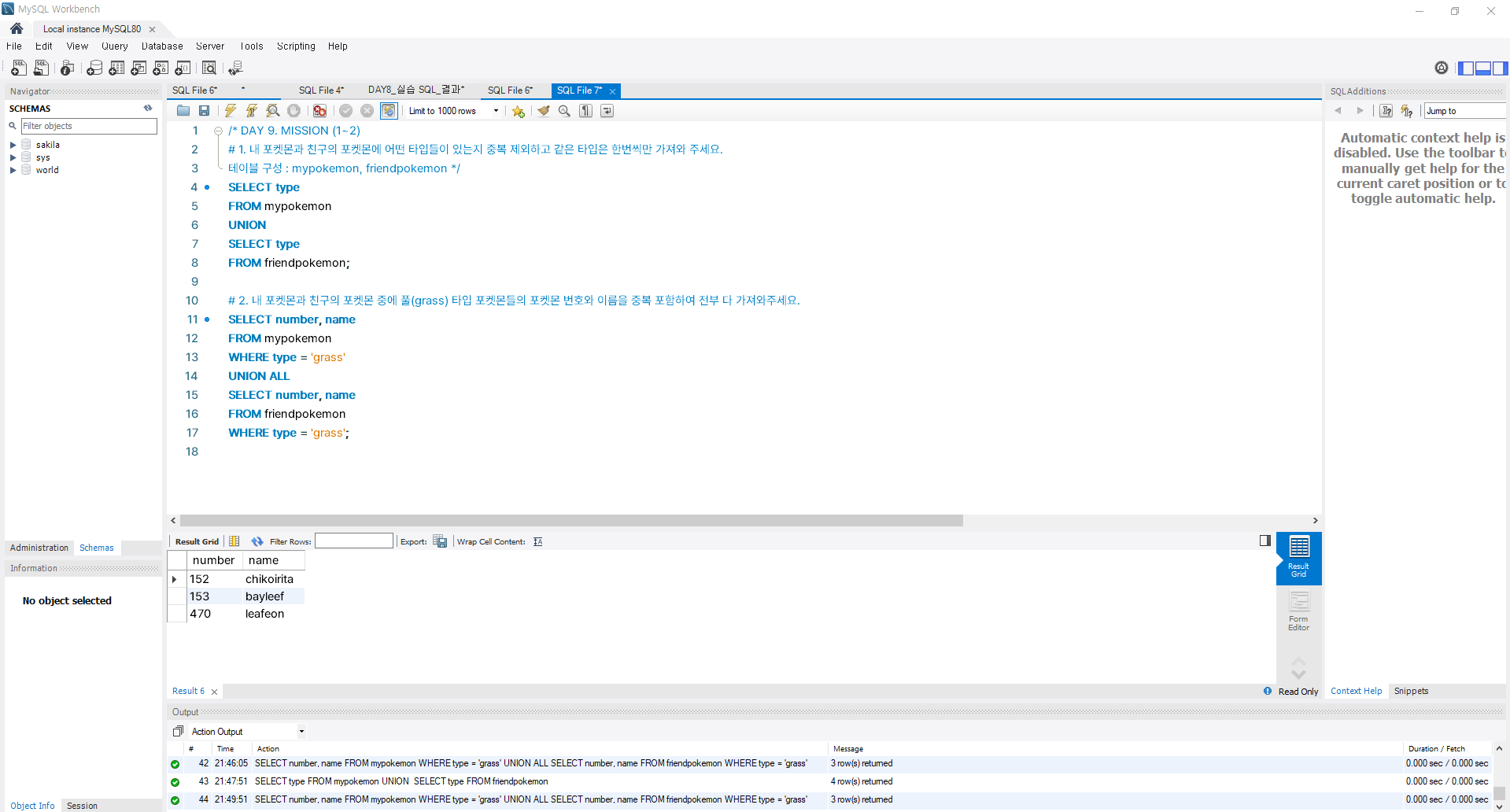
10. 조건에 조건 더하기
1) 조건에 조건 더하기(서브쿼리)
2) SELECT 절의 서브 쿼리
3) FROM 절의 서브쿼리
4) WHERE 절의 서브쿼리
1) 조건에 조건 더하기(서브쿼리)
- 하나의 쿼리 내 포함된 또 하나의 쿼리를 의미함
- 반드시 괄호 안에 있어야 함
- INSET, UPDATE, DELETE 문에도 사용 가능
- 서브쿼리에는 세미콜론(;) 제외하여 작성
# 메인쿼리문 (서브쿼리문)
SELECT (서브쿼리)
FROM (서브쿼리)
WHERE (서브쿼리)
GROUP BY
HAVING (서브쿼리)
ORDER BY (서브쿼리)
-- 서브쿼리문의 경우, 메인쿼리문과 동일한 절로 작성 가능함(SELECT ~ ORDER BY)2) SELECT 절의 서브 쿼리 (=스칼라 쿼리)
- SELECT절의 서브쿼리는 반드시 결과값이 하나의 값이어야 함
> 만약 여러개의 값을 입력 시, 에러 발생
# SELECT 서브쿼리문
SELECT [컬럼이름],
(SELECT [컬럼이름]
FROM [테이블이름]
WHERE 조건식) -- ※ SELECT절의 서브쿼리는 반드시 결과값이 하나여야 함
FROM [테이블이름]
WHERE 조건식;3) FROM 절의 서브쿼리 (=인라인 뷰 서브쿼리)
- SELECT절 서브쿼리 기준처럼 결과값이 하나의 테이블이여야 함
- 서브쿼리로 만든 테이블은 반드시 별명(ALIAS)가 붙어야 함
# FROM절 서브쿼리문
SELECT [컬럼이름]
FROM (SELECT [컬럼이름]
FROM [테이블이름]
WHERE 조건식) AS [테이블 별명] -- ※ FROM절의 서브쿼리는 반드시 결과값이 하나여야 함
WHERE 조건식;4) WHERE 절의 서브쿼리 (=중첩쿼리)
- WHERE절 서브쿼리 또한, 결과값이 하나의 컬럼이어야 함(EXISTS 제외)
> 하나의 컬럼에 여러 개 값 존재 가능
- 연산자와 함께 사용함
> 예로, WHERE [컬럼이름][연산자][서브쿼리] 형식으로 사용
# WHERE절 서브쿼리문
SELECT [컬럼이름]
FROM [테이블이름]
WHERE [컬럼이름][연산자](SELECT [컬럼이름]
FROM [테이블이름]
WHERE 조건식);
-- 연산자의 경우, 아래 표 참고# WHERE절 서브쿼리 비교연산자 활용 예시
| 연산식 활용 | 의미 |
| A = [서브쿼리] | A와 [서브쿼리]결과값이 같다 |
| A != [서브쿼리] | A와 [서브쿼리]결과값은 같지 않다 |
| A > [서브쿼리] | A는 [서브쿼리]결과값보다 크다 |
| A >= [서브쿼리] | A는 [서브쿼리]결과값이랑 같거나 이상이다 |
| A < [서브쿼리] | A는 [서브쿼리]결과값보다 작다 |
| A <= [서브쿼리] | A는 [서브쿼리]결과값이랑 같거나 이하이다 |
# WHERE절 서브쿼리 주요연산자 활용 예시
| 연산자 | 활용예시 | 의미 |
| IN | A IN ([서브쿼리]) | A가 [서브쿼리]의 결과값 내에 있음 |
| ALL | A < ALL ([서브쿼리]) | A가 모든 [서브쿼리]의 결과값보다 작음 |
| A > ALL ([서브쿼리]) | A가 모든 [서브쿼리]의 결과값보다 큼 | |
| ANY | A < ANY ([서브쿼리]) | A가 [서브쿼리]의 결과값보다 하나라도 작음 |
| A > ANY ([서브쿼리]) | A가 [서브쿼리]의 결과값보다 하나라도 큼 | |
| EXISTS* | EXISTS ([서브쿼리]) | [서브쿼리] 결과값이 존재함 |
| NOT EXISTS ([서브쿼리]) | [서브쿼리] 결과값이 존재하지 않음 | |
| ※ EXISTS의 경우, 단독으로 사용 가능하며 결과값이 여러 컬럼이여도 됨(다른 연산자는 하나의 결과값만 가능함) | ||
5) [실습] 서브쿼리로 복잡한 조건을 하나의 쿼리로 만들어보자
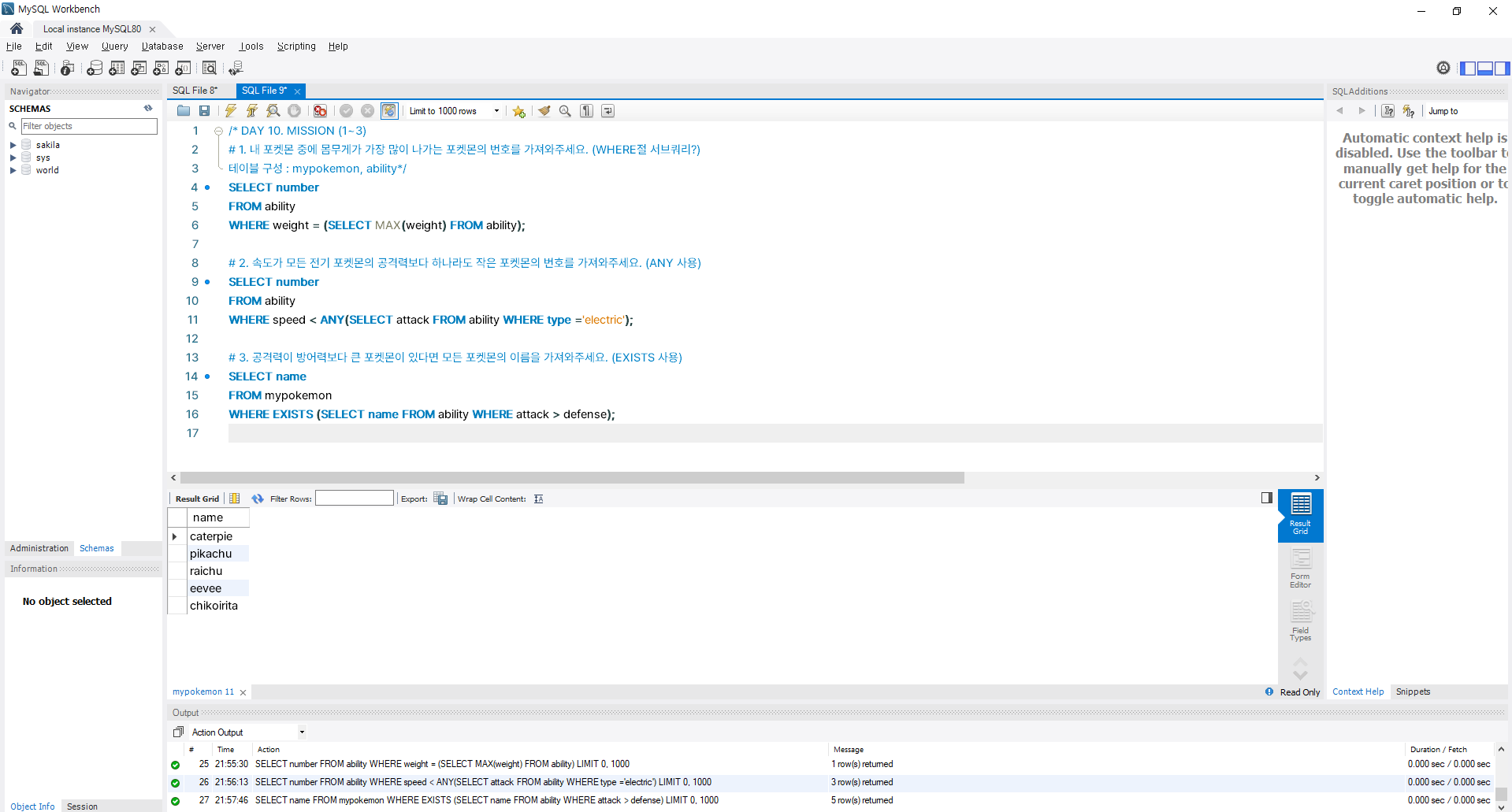
[ NOTE ]
서브쿼리 강의를 듣다보니 JOIN과 기능이 유사해보여, 어떤 차이가 있는지 추가적으로 검색해봤습니다.
아래 링크 참고하여 두 기능 차이를 간략하게 이해했는데 아무래도 계속 써봐야 제대로 숙지할 수 있을 것 같네요.
뒤로 갈수록 헷갈리는 게 늘어나고 있는데 꾸준히 복습 해보면서 개념 파악을 제대로 해야할 것 같습니다.
[MYSQL] 📚 JOIN과 서브쿼리 차이 및 변환 💯 정리
조인(JOIN) vs 서브쿼리(Sub Query) 조인과 서브쿼리는 때로 동일한 결과를 얻을 수 있다. 상황에 따라 조인을 사용하는 것이 훨씬 좋을 때도 있고, 반면에 서브 쿼리를 사용하는 것이 좋을 때도 있다.
inpa.tistory.com
각 쿼리문들이 어떤 식으로 구성되어있는지 구조를 암기하는 것도 중요하지만,
DB 처리속도 측면에서도 어떨 때 어떤 쿼리문을 사용하는 것이 좋을지는 숙련치가 쌓여야할 것 같습니다.
'데이터 분석 > SQL' 카테고리의 다른 글
| [프로그래머스] 코딩테스트 연습 - 헤비 유저가 소유한 장소 (0) | 2023.09.21 |
|---|---|
| [패스트캠퍼스] SQL 강의 학습후기 5주차 (0) | 2023.06.24 |
| [패스트캠퍼스] SQL 강의 학습후기 4주차 (2) | 2023.06.17 |
| [패스트캠퍼스] SQL 강의 학습후기 3주차 (2) | 2023.06.10 |
| [패스트캠퍼스] SQL 강의 학습후기 1주차 (0) | 2023.05.24 |


