
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 코테문제풀이
- 패스트캠퍼스데이터분석부트캠프
- 데이터분석부트캠프
- Programmers
- 프로그래머스
- 국비지원취업
- qgis
- K디지털기초역량훈련
- 아나콘다
- Python
- bigquery
- WSL
- sql강의
- 국비지원교육
- 코딩연습
- mysql
- 코딩테스트문제풀이
- 데이터분석취업
- shp
- 코딩테스트
- SQL
- 패스트캠퍼스
- 데이터분석
- 학습일지
- 패스트캠퍼스기자단
- 부트캠프
- 내일배움카드
- 국비지원
- 패스트캠퍼스부트캠프
- 데이터분석가
- Today
- Total
데이터 리터러시를 위한 발자취
[부트캠프] 데이터분석 학습일지 6주차 본문

데이터분석 부트캠프 학습일지 6주차입니다-!
지난주는 파이썬 미니프로젝트가 진행되었기에, 학습일지 작성 없이 지나갔는데요.
이번주 화요일에 파이썬 미니프로젝트가 종료된 만큼 6주차 학습일지로 돌아왔습니다...ㅋㅋ
이번주부터는 SQL 강의가 진행될 예정인데요.. 벌써 전체 과정 중 2가지 Tool을 다루었네요.. 시간 참 빠릅니다 ㄷㄷ
사실 이번주 학습일지 작성 시작 전 고민되었던 이유가 부트캠프 사전 지원을 통해 SQL 온라인 강의를 수강하였는데요.
그때도 학습일지를 별도 작성한 적이 있고 당시 엄청 세세하게 적었던지라...
고민 끝에 그동안 배운 파이썬 문법과 미니프로젝트 때 사용한 코드 복습 차원에서 가볍게 쓰려고 합니다 :)
# 데이터분석 부트캠프 6주차
1. 파이썬 문법 복습하기
2. 파이썬 미니 프로젝트 소스코드 복습하기
1. 파이썬 문법 복습하기
# 리스트, 튜플, 딕셔너리 문법
- 리스트(list, [])는 값 변경/수정 가능
# 리스트 내 값 추가하기(append)
df = [1,2,3]
a.append(4) # [1,2,3,4] | 마지막 위치에 '4' 추가됨
# 리스트 내 값 삭제하기(pop)
df = [1,2,3]
a.pop() # [1,2] | 마지막 값이 삭제됨- 튜플(tuple, ())은 값 변경 불가 / 조회 가능
# 튜플 내 인덱스 출력하기
df = (1,2,3)
print(a[:2]) # (1,2) | index 기준 0,1번째 숫자 출력함
# 튜플은 치환 시, 에러 발생함
df = (1,2,3)
df[0] = 5 # | index 기준, 0번째 값인 '1'을 '5'로 변경 시 에러 발생함
'''
에러메세지 : 'tuple' object does not support item assignment
'''- 딕셔너리(dict, {})는 키/값 형태로 구성 | {키 : 값}
- 하나의 키에 여러 값 구성 가능
# 여러개 값을 안에 넣을 경우, []로 설정해줌
df ={'car' : ['bus', 'truck', 'taxi'],
'train' : 'ktx'}
# key 얻기
key = df.keys()
print(key) # (['car','train']) 형태로 출력 | type : dict_keys
# key index 출력 시도 시, 에러 발생
print(key[0])
'''
딕셔너리로 설정 시, 특정 index의 값을 불러오려면 에러 발생
에러메세지 : 'dict_keys' object is not subscriptable
에러 해결을 위해선, dict 타입을 list 타입으로 변경해야 함
'''
# dict → list 타입 변경
key_list = list(key)
print(type(key_list)) # type 변경 확인 가능
print(key_list[0]) # key 'car' 정상 출력
# value 얻기
value = df.values()
print(value) # ([['bus', 'truck', 'taxi'], 'ktx']) 형태로 출력 | type : dict_values
'''
value index 출력 시도 시, 위와 같은 에러 발생하기 때문에 list로 변경 후 index 접근 가능함
''' # while true 기반 무한 루프 생성하기
- while True는 무한 루프 반복문을 수행
- 무한 루프 반복문 사용 시, break를 통해 특정 조건이 충족될 때 프로세스를 중지해줘야 함
# while 무한루프문
i = 0
while True :
if i == 5:
print('종료')
break # i가 5와 같을 때 break 선언('종료')
i += 1
print("카운트 :",i)# loc와 iloc 차이 및 사용법
- loc는 location의 약어로, 데이터프레임 행 또는 컬럼의 label 등 인덱싱하는 방법
# 기본 사용방법
df.loc[행 인덱싱 값, 열 인덱싱 값]온라인 강의만으로는 명확하게 이해가 안돼서 파이썬 미니프로젝트 때 사용했던 데이터 기반으로 다시 구성해 봤습니다.
아래는 서울열린데이터광장에서 제공하는 '서울시 공동주택 아파트 정보' 파일을 기반으로 데이터프레임을 구성한 것입니다.
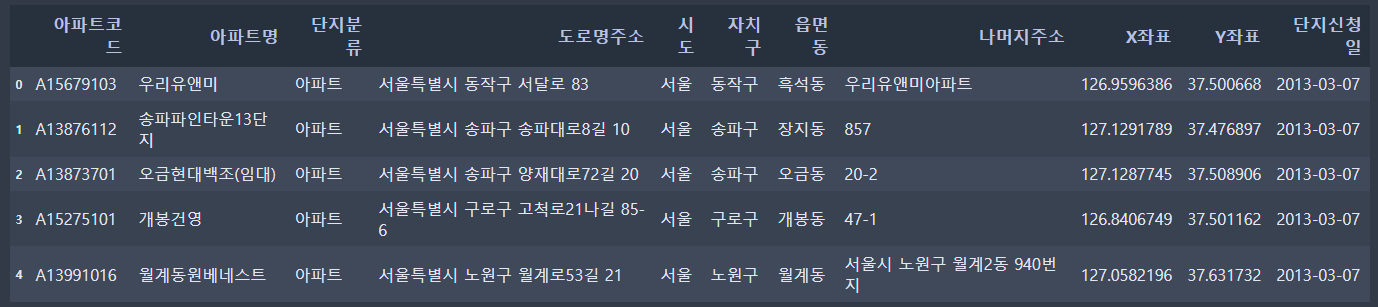
아래와 같이 lco[] 안에 하나의 값을 입력하면 해당하는 하나의 행만 출력됩니다.
실제로도 아래와 같이 temp.loc[0]이라고 입력하면, index가 0인 행만 출력해서 가져온 것을 볼 수 있었습니다.

만약, index가 0인 행 중 특정 컬럼만 보고 싶다면, 열 인덱스 명에 컬럼명을 입력해 주면 아래와 같이 확인 가능합니다.

그리고 미니 프로젝트에선 잘 사용하지 못했지만, 쓰는 습관을 들이면 좋을 슬라이싱을 이용해 특정 범위로 지정할 수 있습니다.
아래처럼 특정 구간을 지정하지 않고, 행/열 인덱스 모두 : 로 입력하면 모든 행과 열이 출력되는 것을 볼 수 있습니다.

이 점을 응용하여, 행 index는 4행까지, 열 index는 '아파트코드'부터 '도로명주소'까지 한꺼번에 가져오려면 아래와 같이 지정할 수 있습니다.

또한, 단지분류가 '도시형 생활주택(아파트)'인 조건만 가져오고 싶으면 아래와 같이 사용 가능합니다.

- iloc는 integer location의 약어로, 데이터프레임의 행이나 컬럼 순서를 나타내는 정수로, 특정 값을 추출해 오는 방법
- iloc의 경우, 컴퓨터가 읽기 좋은 방법(숫자)으로 데이터가 있는 위치(순서)에 접근하는 방법
# 기본 사용방법
df.iloc[행 인덱스, 열 인덱스]사실 이렇게 설명을 해도 이해가 되질 않아 상기 예제 코드들처럼 loc의 조건을 동일하게 iloc로 적용해 봤습니다.

보시면 상기 이미지처럼 temp.loc[0,1]을 입력하면 'KeyError: 1' 란 에러가 발생하는데요.
실험 삼아 temp.iloc[0,'아파트명']라고 입력하니 아래와 같이 에러(ValueError)가 발생하며 정상 출력되지 않았습니다.
에러내용을 살펴보면, iloc는 정수(int) 값만 들어가야 하는데 문자열로 값이 입력되면서 에러가 발생되었음을 알 수 있습니다.
ValueError: Location based indexing can only have [integer, integer slice (START point is INCLUDED, END point is EXCLUDED), listlike of integers, boolean array] types이러한 점을 주의하여, iloc로 행 index는 4행까지, 열 index는 '아파트코드'부터 '도로명주소'까지 한꺼번에 가져오려면 아래와 같이 지정할 수 있습니다.

이렇게 loc와 iloc의 차이점을 코드 작성을 통해 살펴봤는데요.
개인적으론 iloc는 인덱싱할 행, 열이 소수일 때는 쓰기 편할지도 모르겠지만, 조건을 지정하거나 열이 많을 때는 loc를 쓰는 게 더 편리할 것 같다는 생각이 들었습니다.
워낙 파이썬은 사용자마다 작성 방식이 다른 만큼 본인에게 편리하게 쓰면 될 것 같아요.
한 번 이렇게 정리하는데 도움이 된 참고사이트는 아래 References에서 확인할 수 있습니다-!
# References
[pandas] 2-1. loc와 iloc 차이와 사용방법
파이썬 기초 문법을 공부할 때 인덱싱(indexing) 개념에 대해 배웠을 것이다. '인덱싱'에 대해 잘 모른다면 (클릭). 인덱싱은 데이터 프레임에도 적용할 수 있는데, 판다스에서 특정 행(row)나 열(colum
bigdaheta.tistory.com
[pandas] 2-2. loc와 iloc 차이와 사용방법
🖇 이전 글 [pandas] 2-1. loc와 iloc 차이와 사용방법 파이썬 기초 문법을 공부할 때 인덱싱(indexing) 개념에 대해 배웠을 것이다. '인덱싱'에 대해 잘 모른다면 (클릭). 인덱싱은 데이터 프레임에도 적
bigdaheta.tistory.com
# matplotlib, seaborn 기반 혼합차트 만들기
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 예시 데이터 & 코드
data = {
'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May'],
'Sales': [100, 150, 200, 180, 230],
'Profit': [20, 30, 40, 35, 50]
}
df = pd.DataFrame(data)
# matplotlib와 seaborn을 사용하여 혼합형 차트 그리기
plt.figure(figsize=(8, 6))
# 선 그래프
sns.lineplot(x='Month', y='Sales', data=df, marker='o', label='Sales')
# 막대 그래프
sns.barplot(x='Month', y='Profit', data=df, alpha=0.5, color='gray', label='Profit')
plt.xlabel('Month')
plt.ylabel('Value')
plt.title('Mixed Chart: Sales and Profit')
plt.legend()
plt.show()
2. 파이썬 미니 프로젝트 소스코드 복습하기
# 서울시 따릉이 마스터 정보 API로 받아오기
공공데이터포털이나 기타 공공데이터플랫폼의 경우, csv 파일을 제공하기 때문에 API를 안 쓰는 경우도 많습니다
하지만, 배웠던 것을 학습해 볼 겸.. 서울시 따릉이 마스터 정보를 API로 가져오는 코드를 작성했었는데요.
이후 이어질 위/경도 좌표변환 코드 부문과 같이 과정 정리 겸 복습 차원에서 코드 정리해 보겠습니다.
- 서울시 따릉이대여소 마스터 정보 (서울열린데이터광장)
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
우선 API 사용을 위해 발급받은 키는 아래 코드를 통해 정상처리 되는 점 확인하였습니다.
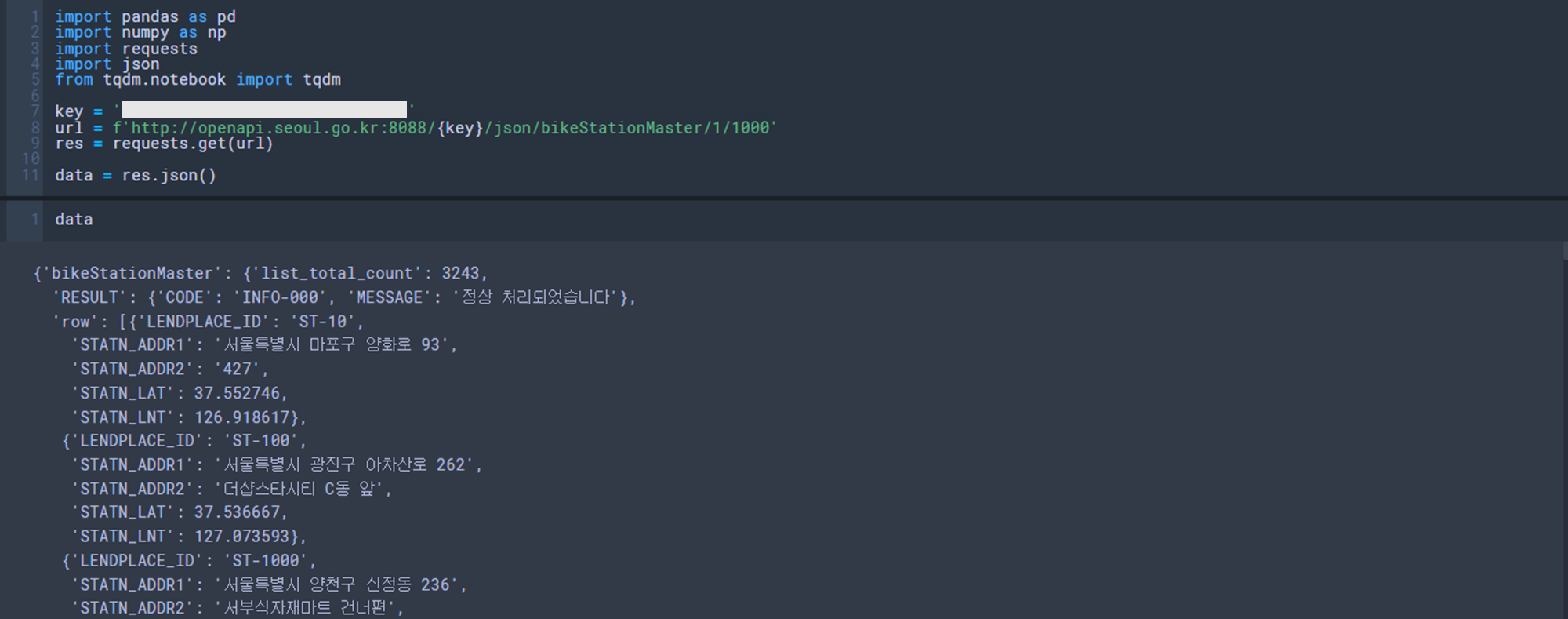
상기 코드 이미지와 같이 총 데이터 건 수는 3,243건이었으며, 아래처럼 코드 작성해서도 확인 가능합니다.

이후 API 데이터를 데이터프레임으로 불러오기 위하여 아래와 같이 변수 설정 및 for 반복문을 통해 데이터프레임으로 설정해 주었습니다.
# 참고코드
import requests
import json
import math
from tqdm.notebook import tqdm
start = 1
end = total_num
RENT_ID = []
STA_ADD1 = []
STA_ADD2 = []
STA_LAT = []
STA_LONG = []
#RealTime = data['bikeStationMaster']['row']
for i in tqdm(range(1,math.ceil(total_num/1000)+1)):
# 데이터요청은 한번에 최대 1000건을 넘을 수 없음
# 요청종료위치에서 요청시작위치를 뺀 값이 1000을 넘지 않도록 수정
end = i*1000
start = end - 1000 +1
if end > total_num:
end = total_num
key = '인증키번호'
url = f'http://openapi.seoul.go.kr:8088/{key}/json/bikeStationMaster/{start}/{end}'
res = requests.get(url)
data = res.json()
for u in data['bikeStationMaster']['row'] :
RENT_ID.append(u['LENDPLACE_ID'])
STA_ADD1.append(u['STATN_ADDR1'])
STA_ADD2.append(u['STATN_ADDR2'])
STA_LAT.append(u['STATN_LAT'])
STA_LONG.append(u['STATN_LNT'])
df = pd.DataFrame({'RENT_ID':RENT_ID,'STA_ADD1':STA_ADD1, 'STA_ADD2':STA_ADD2, 'STA_LAT':STA_LAT,\
'STA_LONG' : STA_LONG })
df- 출력결과

# 카카오 API 기반 도로명 데이터 위/경도 좌표 변환하기
파이썬 미니 프로젝트를 수행하면서, 카카오 API를 이용하여 도로명 데이터 기반 위/경도 변환 작업을 진행하였는데요.
과정 정리 겸 복습 차원에서 사용했던 코드를 남겨두려고 합니다.
아마 위/경도 변환해 주는 API는 카카오 외에도 구글이나 네이버 등 다양하게 있는 걸로 알고 있습니다.
Kakao Developers
카카오 API를 활용하여 다양한 어플리케이션을 개발해보세요. 카카오 로그인, 메시지 보내기, 친구 API, 인공지능 API 등을 제공합니다.
developers.kakao.com
저는 그중, 카카오 API로 좌표변환 작업을 진행했는데 API key는 상기 사이트에서 발급받을 수 있습니다.
발급받았다면, '내 애플리케이션'에서 아래와 같이 발급받은 API key를 확인 가능합니다.
좌표 변환에 사용된 데이터는 국토부 실거래가 공개시스템에서 제공하는 아파트(매매) 한정 데이터를 전처리하여 아래와 같이 전처리 후, '도로명' 컬럼을 이용하여 변환 진행하였습니다.

# 코드 참고
import requests, json
import pandas as pd
import time
# 카카오 API 기반 호출 함수
def get_location(address):
url = 'https://dapi.kakao.com/v2/local/search/address.json?query=' + address
# 'KaKaoAK '는 그대로 두고 개인키 입력.
headers = {"Authorization": "KakaoAK 개인키복붙"}
api_json = json.loads(str(requests.get(url,headers=headers).text))
return api_json
# get_location 함수 기반 x,y좌표 추출 함수
def result_location(i):
api_json = get_location(test_data['도로명'][i])
if api_json['documents']:
address = api_json['documents'][0]['address']
test_data.loc[i,'x'] = address['x'];
test_data.loc[i,'y'] = address['y']
else:
test_data.loc[i,'x'], test_data.loc[i,'y'] = None, None
print(i, '번째 변환 완료...')
# temp2 기반 x,y 좌표 변환 후, csv로 저장
test_data = temp2
for i in range(0,,1):
split=[]
if test_data['도로명'][i].endswith(']'):
split = test_data['도로명'][i].split('[') # split은 리스트 반환
test_data['도로명'][i] = split[0]
i = 0
while i<=len(test_data['도로명']):
try:
result_location(i)
i+=1
except:
print('time.sleep 적용합니다.')
time.sleep(2)
result_location(i)
i+=1
test_data.to_csv('include_xy.csv', encoding='cp949')# References
그래도 이렇게 복습 차원에서 헷갈렸던 파이썬 문법들을 정리해 보니 좀 더 이해가 잘 되는 것 같습니다.
사실 온라인 강의만 해도 들을 수 있는 게 정말 많던데... 완주하는 그날까지 계속 틈틈이 들어보려고 합니다.
이제 내일부터 SQL 강의가 본격적으로 시작하는데요.
그래도 부트캠프 수강 전 SQL 사전 강의를 들어서 파이썬 보단 덜 버벅거릴 거 같긴 한데...
계속 감을 잃어버리지 않기 위해 코팅테스트 사이트에서 연습 중입니다....ㅋㅋ
남은 기간도 파이팅입니다 :)
번외로, SQL 강의 학습 당시 기록해둔 1~2주차 링크 남겨둡니다!
이번주 수,목 진행된 온라인 강의 내용을 포함하고 있는 점 참고 부탁드려요~
'부트캠프 > [패스트캠퍼스] 데이터분석 9기' 카테고리의 다른 글
| 패스트캠퍼스 데이터분석 피어세션 후기 (0) | 2023.08.06 |
|---|---|
| [부트캠프] 데이터분석 학습일지 7주차 (0) | 2023.08.03 |
| 패스트캠퍼스 데이터분석 현직자 특강 후기 (0) | 2023.07.26 |
| [부트캠프] 데이터분석 학습일지 4주차 (0) | 2023.07.14 |
| [부트캠프] 데이터분석 학습일지 3주차 (0) | 2023.07.07 |



